Differential Abundance with TrajAtlas#
Setup#
import numpy as np
import scanpy as sc
import pandas as pd
import TrajAtlas as tja
sc.settings.verbosity = 3
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = (7, 7)
About#
To learn about TrajDiff, please read TrajDiff
Datasets#
In this tutorial, we continue with the adata we created in OPCST projecting.
adata=sc.read("../data/3.19_adata_immediate_step1.h5ad")
adata
AnnData object with n_obs × n_vars = 15079 × 22076
obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'percent_mito', 'RNA_snn_res.0.5', 'seurat_clusters', 'group', 'sample', 'pseduoPred', 'pred_level1_anno', 'pred_level2_anno', 'pred_level3_anno', 'pred_level4_anno', 'pred_level5_anno', 'pred_level6_anno', 'pred_level7_anno', 'pred_lineage_fibro', 'pred_lineage_lepr', 'pred_lineage_msc', 'pred_lineage_chondro', 'lineageSum', 'Cell'
var: 'vst.mean', 'vst.variance', 'vst.variance.expected', 'vst.variance.standardized', 'vst.variable'
uns: 'group_colors', 'neighbors', 'pred_level2_anno_colors', 'pred_level3_anno_colors', 'pred_lineage_chondro_colors', 'pred_lineage_fibro_colors', 'pred_lineage_lepr_colors', 'pred_lineage_msc_colors', 'umap'
obsm: 'X_umap', 'scANVI'
layers: 'counts'
obsp: 'connectivities', 'distances'
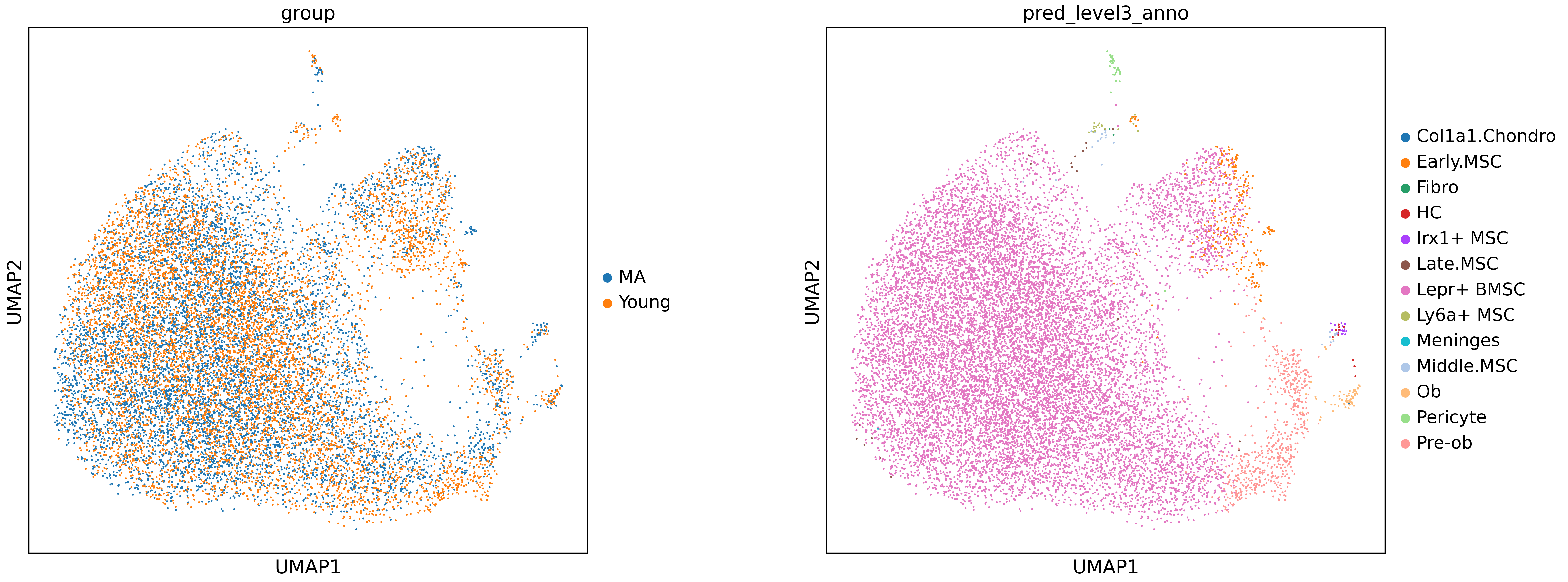
sc.pl.umap(adata, color=["group","pred_level3_anno"], wspace=0.3, size=8)
/home/gilberthan/anaconda3/envs/scarches/lib/python3.8/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
/home/gilberthan/anaconda3/envs/scarches/lib/python3.8/site-packages/scanpy/plotting/_tools/scatterplots.py:392: UserWarning: No data for colormapping provided via 'c'. Parameters 'cmap' will be ignored
cax = scatter(
adata.obs[["sample","group"]].drop_duplicates()
| sample | group | |
|---|---|---|
| AAACCCATCCAATCCC-1_1 | BmscAging_Young_MA1 | MA |
| AAACCCAAGCTAAACA-1_2 | BmscAging_Young_MA2 | MA |
| AAACCCAGTAACATAG-1_3 | BmscAging_Young_MA3 | MA |
| AAACCCACAGCGTACC-1_4 | BmscAging_Young_MA4 | MA |
| AAACCCACAAAGGATT-1_5 | BmscAging_Young_MA5 | MA |
| AAACCCAAGCGTTAGG-1_10 | BmscAging_Young_Young1 | Young |
| AAACCCAGTTAAGAAC-1_11 | BmscAging_Young_Young2 | Young |
| AAACGAAGTACCATAC-1_12 | BmscAging_Young_Young3 | Young |
| AAACCCACACGAAAGC-1_13 | BmscAging_Young_Young4 | Young |
| AAACGAACACCTCGTT-1_14 | BmscAging_Young_Young5 | Young |
tdiff=tja.diff.Tdiff()
Building KNN graph (standard milo pipeline)#
We followed the standard milo pipeline. The n_neighbors parameter represents the smallest possible size of the neighborhood in which we will quantify differential abundance (i.e., with k=50, the smallest neighborhood will have 50 cells). The value of k should increase with the sample count.
sc.pp.neighbors(tdata['rna'], use_rep='scANVI', n_neighbors=200, n_pcs=15)
tdiff.make_nhoods(tdata['rna'], prop=0.08)
tdata = tdiff.count_nhoods(tdata, sample_col="sample")
computing neighbors
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:38)
/home/gilberthan/anaconda3/envs/scarches/lib/python3.8/site-packages/anndata/_core/anndata.py:117: ImplicitModificationWarning: Transforming to str index.
warnings.warn("Transforming to str index.", ImplicitModificationWarning)
Differential abundance testing#
Here, we calculated the differential abundance for each neighborhood using a Generalized Linear Model (GLM). Differing from the standard milo pipeline, we projected the results of the differential abundance onto the pseudotime axis. We divided the pseudotime axis into n intervals and applied a binomial model to each interval. Next, we shuffled the group labels to perform permutation null hypothesis testing to obtain lambda. Through this process, we are able to identify the differentiation stage with differential abundance.
tdiff.da(tdata, design='~group',model_contrasts='groupYoung-groupMA',time_col="pseduoPred",shuffle_times=20,FDR=0.05)
Permutation null hypothesis testing.....
Running differential abundance.....
Projecting neighborhoods to pseudotime axis.....
Done!
tdata
MuData object with n_obs × n_vars = 15079 × 22076
3 modalities
rna: 15079 x 22076
obs: 'orig.ident', 'nCount_RNA', 'nFeature_RNA', 'percent_mito', 'RNA_snn_res.0.5', 'seurat_clusters', 'group', 'sample', 'pseduoPred', 'pred_level1_anno', 'pred_level2_anno', 'pred_level3_anno', 'pred_level4_anno', 'pred_level5_anno', 'pred_level6_anno', 'pred_level7_anno', 'pred_lineage_fibro', 'pred_lineage_lepr', 'pred_lineage_msc', 'pred_lineage_chondro', 'lineageSum', 'Cell', 'nhood_ixs_random', 'nhood_ixs_refined', 'nhood_kth_distance'
var: 'vst.mean', 'vst.variance', 'vst.variance.expected', 'vst.variance.standardized', 'vst.variable'
uns: 'group_colors', 'neighbors', 'pred_level2_anno_colors', 'pred_level3_anno_colors', 'pred_lineage_chondro_colors', 'pred_lineage_fibro_colors', 'pred_lineage_lepr_colors', 'pred_lineage_msc_colors', 'umap', 'nhood_neighbors_key'
obsm: 'X_umap', 'scANVI', 'nhoods'
layers: 'counts'
obsp: 'connectivities', 'distances'
tdiff: 10 x 707
obs: 'group', 'sample'
var: 'index_cell', 'kth_distance', 'null', 'group1_cpm', 'group2_cpm', 'logFC', 'logCPM', 'F', 'PValue', 'FDR', 'SpatialFDR', 'time', 'range_down', 'range_up', 'Accept', 'logChange'
uns: 'sample_col'
varm: 'whole_cpm'
pseudobulk: 0 x 0
Visualization#
We utilized PyComplexHeatmap to visualize the cell abundance of every sample and the statistics. The TrajDiff generated four statistics. Group1 and Group2 represent the mean abundance of two groups (Young and MA) in every pseudotime interval. Diff_abundance indicates the cell abundance difference between Group1 (Young) and Group2 (MA). FDR indicates the significance of the difference.
meta=adata.obs
sampleDf=meta[["sample","group"]].drop_duplicates()
sampleDf.index=sampleDf["sample"]
import PyComplexHeatmap as pch
row_ha = pch.HeatmapAnnotation(group=pch.anno_simple(sampleDf.group,cmap='Set1',
add_text=True,text_kws={'color':'white','rotation':-90,'fontweight':'bold','fontsize':10,},
legend=True),
axis=0,verbose=0,label_kws={'rotation':90,'horizontalalignment':'left'})
tdiff.plotDAheatmap(tdata,row_split=sampleDf.group,left_annotation=row_ha)
Starting plotting..
Starting calculating row orders..
Reordering rows..
Starting calculating col orders..
Reordering cols..
Plotting matrix..
Collecting legends..
Plotting legends..
Estimated legend width: 17.767277777777778 mm
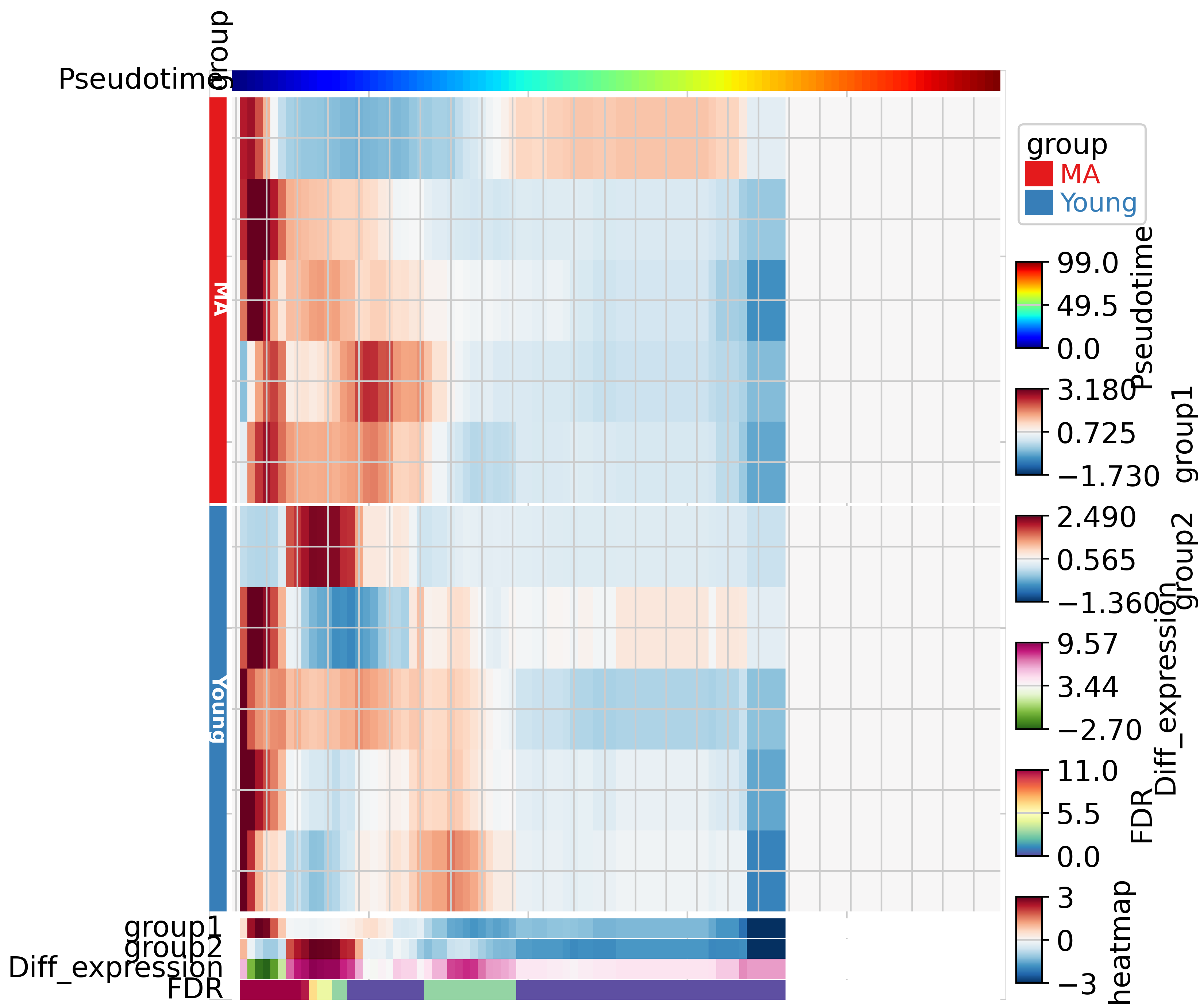
In the results above, we observed that the differences in cell abundance are concentrated at the early and middle stages of differentiation. Specifically, at the early stage, MA has a higher cell abundance, whereas at the middle stage, Young has a higher cell abundance. We did not detect any differences at the late stage, which may be due to the low cell abundance of both samples. Overall, these results are aligned with our study, which detected cell abundance differences in LepR+ BMSC OPCST between young and adult individuals.